
Evaluate AI agents & application to measure performance, catch regressions, simulate tricky scenarios, and ship to production with confidence.
Define your own code or LLM evaluators to automatically test your AI pipelines against your custom criteria, or define human evaluation fields to manually grade outputs.
Evaluation runs can be logged programmatically and integrated into your CI/CD workflows via our SDK, allowing you to check for regressions.
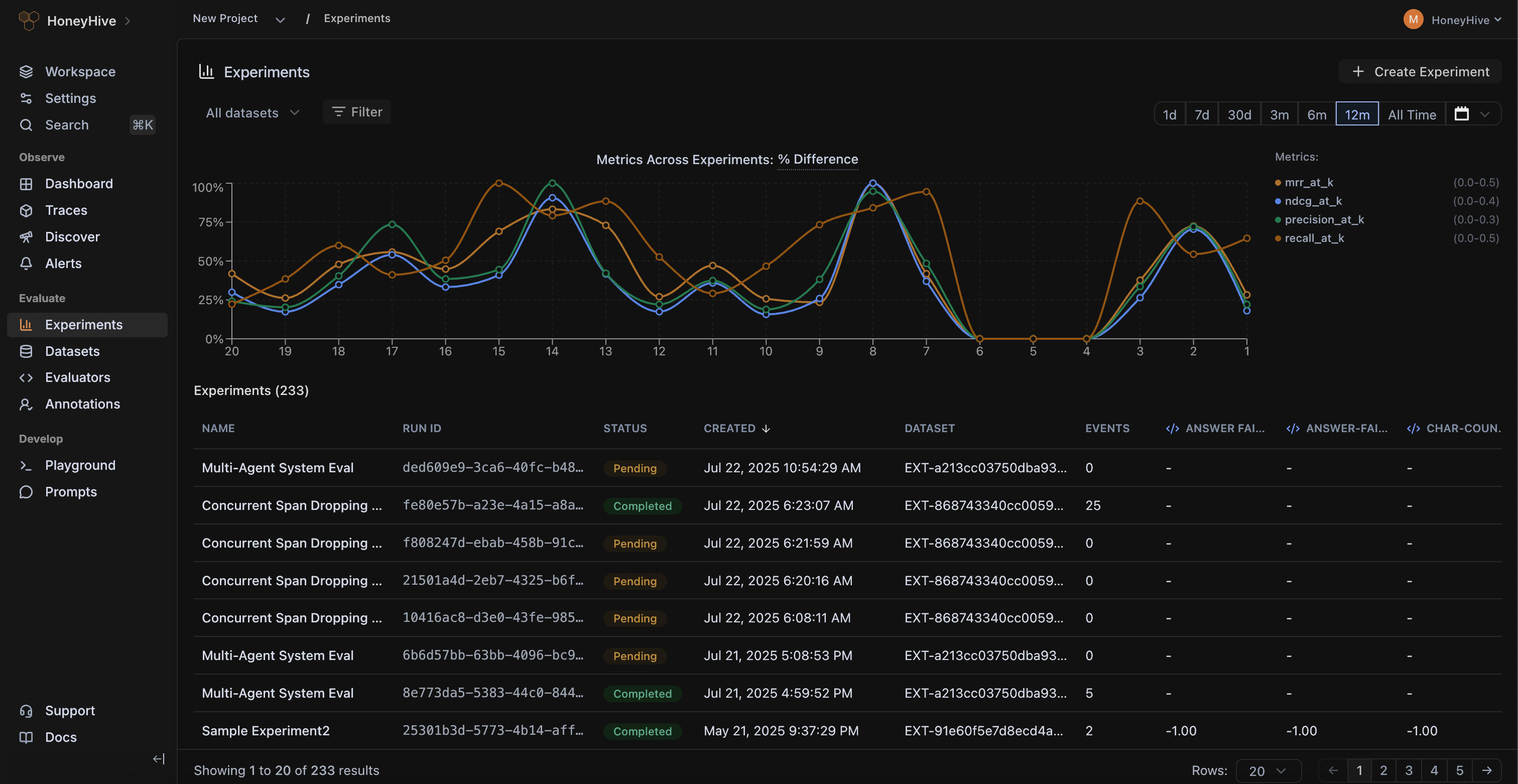
Get detailed visibility into your entire LLM pipeline across your run, helping you pinpoint sources of regressions in your pipeline as you run experiments.
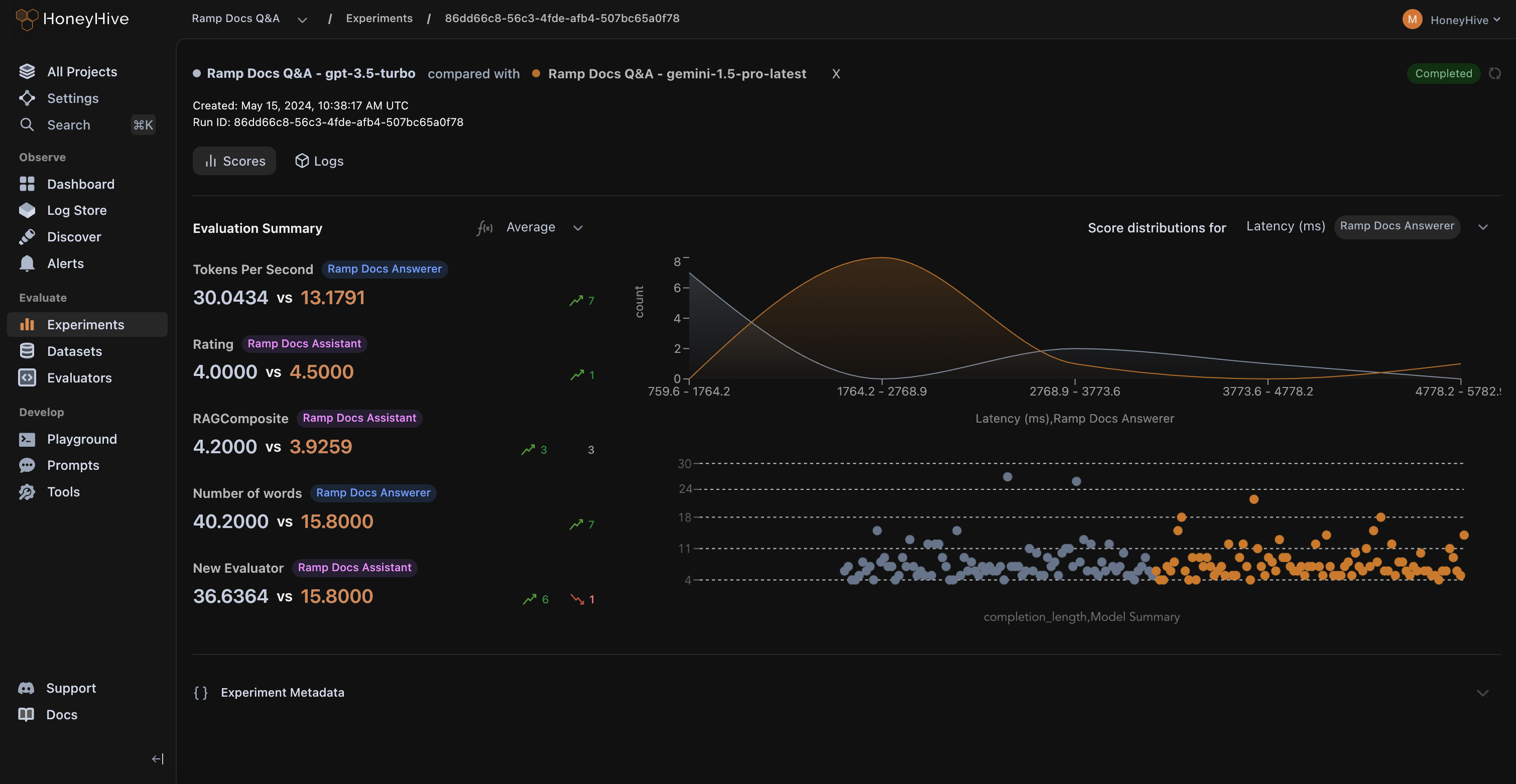
Save, version, and compare evaluation runs to create a single source of truth for all experiments and artifacts, accessible to your entire team.
Capture underperforming test cases from production and add corrections to curate golden datasets for continuous testing.
We automatically parallelize requests and metric computation to speed up large evaluation runs spanning thousands of test cases.
HoneyHive enables you to test AI applications just like you test traditional software, eliminating guesswork and manual effort.

Evaluate prompts, agents, etc. against datasets
Scale human annotations with queues and custom criteria
Compare experiments and spot regressions in CI
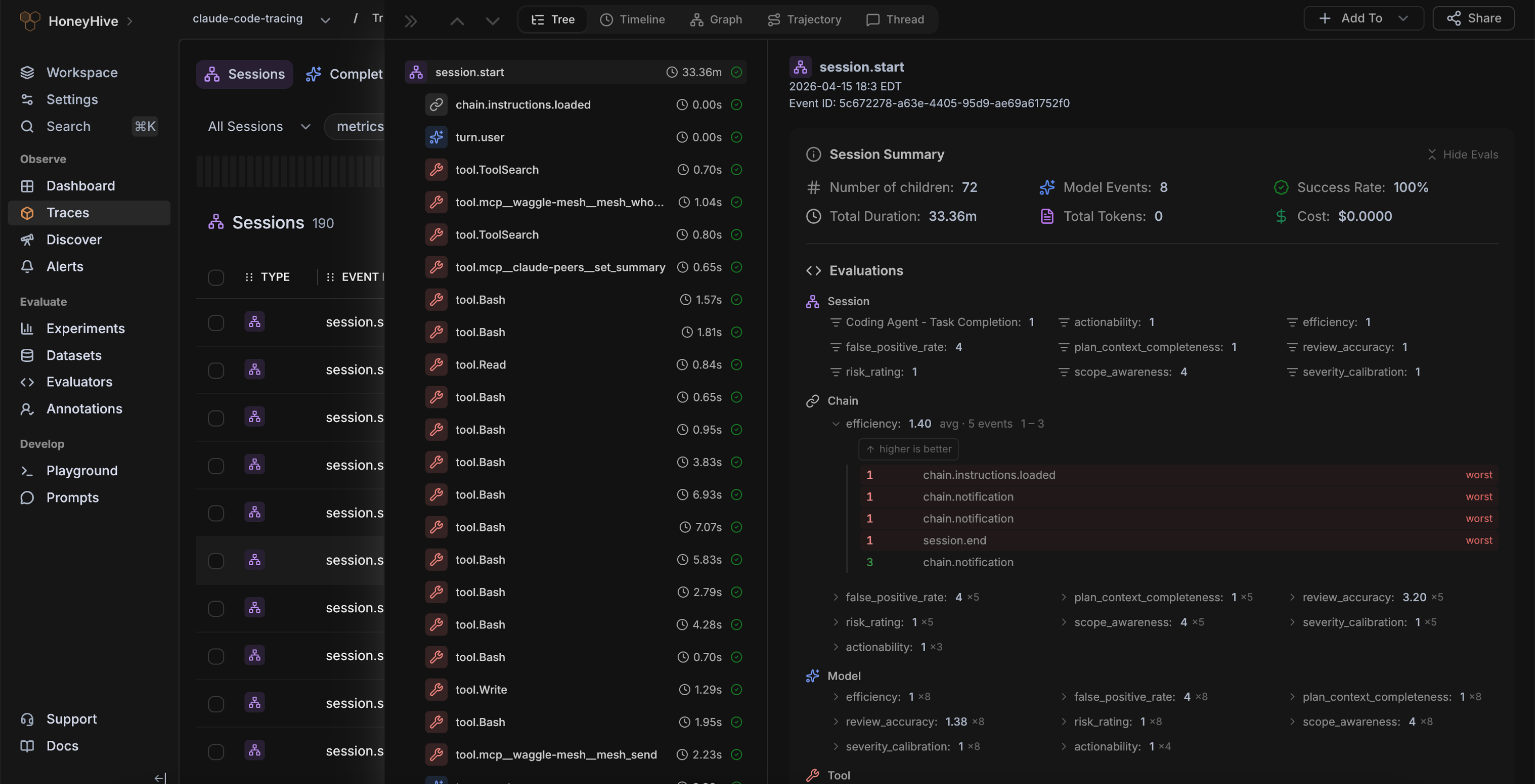
Agents fail due to due to cascading failures across tool calls, reasoning steps, and more. With full visibility into the entire sequence of actions, you can quickly pinpoint errors and iterate with confidence.

Debug agents with distributed traces across complex agentic systems
.png)
Understand agent structure and critical paths with graphs
.png)
OpenTelemetry-native, integrates with leading frameworks
HoneyHive enables you to filter and label underperforming data from production to curate "golden" evaluation datasets to test and evaluate your application.
Curate datasets from production, or synthetically generate using AI
Invite domain experts to annotate and provide ground truth labels
Manage and version evaluation datasets across your project
.png)
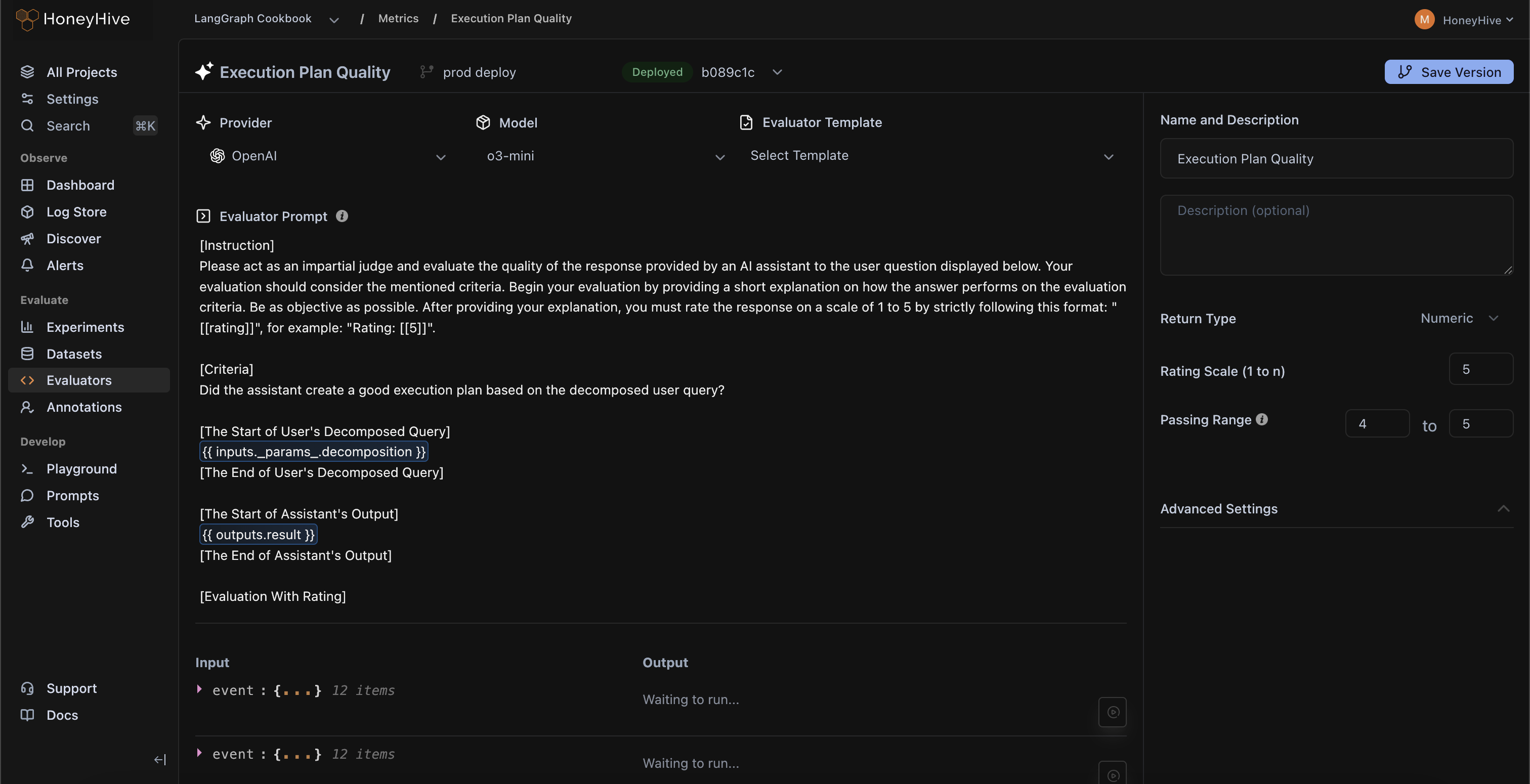
Every use-case is unique. HoneyHive allows you to build your own LLM evaluators and validate them within the evaluator console.
.png)
Test faithfulness and context relevance across RAG pipelines
Write assertions to validate JSON structures or find keywords
Implement custom moderation filters to detect unsafe responses
Use LLMs to critique agent trajectory over multiple steps
OpenTelemetry-native. Automatically trace LLM requests and agent frameworks using OpenTelemetry.
Continuous integration. Integrate HoneyHive into your existing CI workflow using GitHub Actions.
Flexible. Use pre-built evaluators, define your own, or use any 3rd-party evaluators.
.png)
HoneyHive powers observability and evaluation across mission-critical AI systems at CBA, enabling safe and responsible deployment of AI agents serving 17M+ consumers.
.jpg)